

La previsione del crimine in tempo reale, con l’intelligenza artificiale, è oggi una priorità per la comunità scientifica che si impegna a sviluppare modelli statistici sempre più precisi ed efficaci. Gli obiettivi degli esperti incaricati di sviluppare gli algoritmi riguardano in primis l’individuazione di luogo e tempo di un probabile crimine. In secondo luogo, si concentrano su causa e vittima. Analizziamo lo scenario che le nuove tecnologie prospettano in questo ambito e che stanno aprendo nuovi fronti per la sicurezza dei cittadini.
“Signor Marks, in nome della sezione Precrimine di Washington, la dichiaro in arresto per il futuro omicidio di Sarah Marks e Donald Dubin, che avrebbe dovuto avere luogo oggi 22 Aprile alle ore 8 e 04 minuti”.
-Dal film: “Minority Report”, 2002, Steven Spielberg
Indice degli argomenti
I modelli di polizia predittiva con l’intelligenza artificiale
I dipartimenti di polizia che utilizzano l’analisi predittiva per la prevenzione del crimine sono attivi nelle nostre città da anni.
Esplora i 5 trend chiave che stanno rivoluzionando la crescita della ROBOTICA!
Tutti i progetti di predictive policing usano dati storici (soprattutto quelli che si riferiscono ad un passato molto vicino) i quali, se incrociati con le tecnologie avanzate nel modo giusto, possono condurre alla definizione di trend dei comportamenti criminali, facilmente prevedibili e individuabili.
Attualmente i modelli di polizia predittiva usano diverse metodologie a seconda dell’obiettivo che si vuole raggiungere e dei dati di cui si dispone. In particolare è possibile dividere le tecniche predittive in quattro classi:
- La prima è composta dalle tecniche di analisi statistica classiche, che utilizzano modelli multivariati basati su regressioni e in generale tecniche supervisionate oltre a modellistica basata sulle time-series con procedure di destagionalizzazione annesse.
- La seconda classe include i metodi semplici, che sono quelli che non richiedono un’ampia mole di dati o un processo complesso di calcolo, ad esempio i metodici euristici basati su indici e checklists piuttosto che su big data.
- La terza classe è formata dalle cosiddette applicazioni complesse, le quali richiedono oltre che un numero considerevole di dati analizzabili anche nuove e sofisticate tecniche computazionali, rientrano in questa categoria i modelli near-repeat.
- La quarta classe comprende i metodi personalizzati, che non sono nient’altro che metodi statistici e tecniche già sperimentate che vengono adattate a modelli più specifici di supporto alla polizia predittiva. Per esempio modelli e metodi di machine learning utilizzati per creare heat maps.
Per quanto riguarda la classificazione dei modelli in base al loro obiettivo, viene focalizzata l’attenzione circa il luogo e il momento dell’atto criminoso. Per prevedere il luogo del reato utilizzando soltanto i dati storici dei crimini la categoria analitica da utilizzare è la hot spot analysis, che include tecniche predittive come la grid mapping, i covering ellipses e metodi di misurazione basati su stime di densità Kernel; se invece l’analista ha a disposizione un range più esteso di dati è possibile utilizzare la categoria analitica dei metodi di regressione oppure le tecniche predittive supervisionate e delle tecniche non supervisionate di clustering.
I modelli analitici basati sul near-repeat consentono di predire il luogo del crimine in un futuro molto prossimo basandosi solamente sui dati dei crimini, attraverso tecniche di predizione di self-exciting point process e promap.
Sicurezza, così si individua il luogo del (futuro) crimine
Per predire il momento in cui un’azione criminale ha probabilità di essere compiuta risulta plausibile utilizzare due categorie analitiche differenti: l’analisi spazio temporale (utilizza i dati storici dei crimini e i dati temporali creando dei modelli di predizione come le heat maps, gli additive models) oppure basarsi su dati geografici associati al rischio creando modelli predittivi geo-spaziali.
La hot spot analysis è una delle categorie di tecniche maggiormente utilizzate dagli analisti dei dipartimenti di polizia. Grazie a questo tipo di analisi, infatti, è possibile individuare le zone a più alto rischio di criminalità procurandosi solamente i dati riguardanti le azioni criminose passate. L’assunto metodologico a sostegno di questa analisi è che il crimine non è casuale e tantomeno uniforme, ma alcune caratteristiche rendono alcune aree e determinati momenti della giornata o della settimana più appropriati al crimine.
Gli hot spot (le “zone calde”) appaiono grazie all’incrocio tra dati storici sui reati e altre variabili o informazioni presenti nei dataset e vengono poi visualizzati sulla mappa. La categoria della hot spot analysis comprende, da una parte, l’utilizzo della tecnica predittiva delle grid maps la quale “mira” a suddividere, attraverso l’uso di coordinate cartesiane, l’area oggetto di analisi (ad esempio una città) in tante piccole partizioni (celle) e a misurare la quantità di reati accaduti per ogni “cella”. Sulla base di questa ripartizione è possibile individuare le zone calde presenti sulla mappa. Dall’altro lato, al fine di individuare zone più ristrette e precise vengono visualizzati sulla mappa dei raggruppamenti ellittici (covering ellipses) definiti tramite clusters che riuniscono le zone calde e le zone appena limitrofe.
Questo approccio risulta molto utile poiché segnala geograficamente tutti i crimini previsti: l’algoritmo maggiormente utilizzato è il nearest neighbor hierarchical clustering (NNHC).
Tecno-polizia, chi adotta la hot spot analysis
L’uso della tecnica di hot spot analysis è stata provata durante l’operazione SAVVY condotta dalla polizia delle West Midlands: lo studio ha individuato 150 metri quadrati di hot spots e ha concentrato pattugliamenti di agenti nella zona per quindici minuti, tre volte durante i periodi di picco delle azioni criminose. Il risultato del progetto ha portato ad una riduzione significativa nelle aree di criminalità catalogate di medio e alto livello.
Tecniche basate su regressioni sono state utilizzate in campo di polizia predittiva dal dipartimento di polizia di Washington D.C. per un’analisi predittiva dei reati di rapine. La figura 1 mostra, attraverso i colori delle celle, il rischio dei furti previsti dal modello. Le previsioni sono formulate in base ai dati storici di una singola cella e delle celle adiacenti: importante sottolineare che le variabili considerate non si riferiscono soltanto ai furti ma ai dati di altri cinque tipi di crimine (variabili esplicative, già selezionate in precedenza).
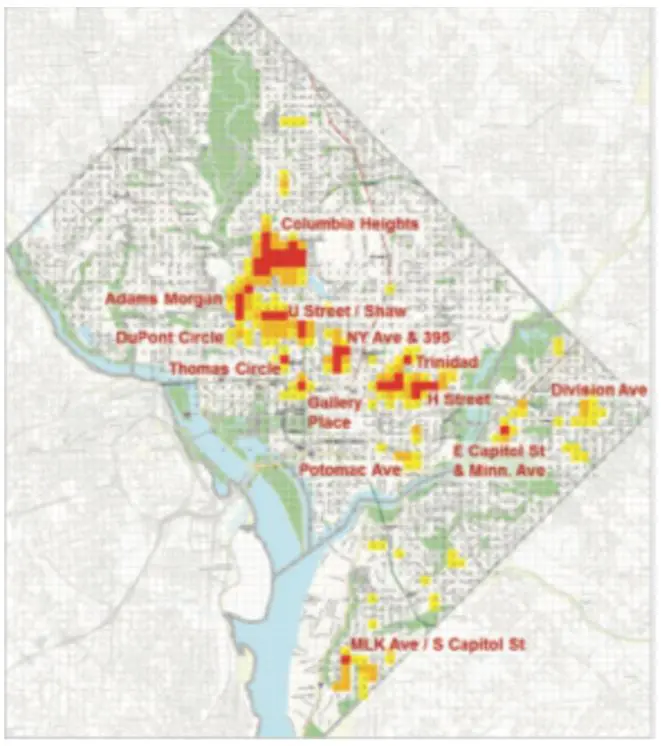
I modelli near-repeat si basano sull’assunto teorico della multi-vittimizzazione che ultimamente in criminologia sta giocando un ruolo primario: le ricerche hanno dimostrato appunto che coloro che hanno subito in passato dei reati sia personali sia a una qualche forma di patrimonio hanno più probabilità di subirne nuovamente. Allo stesso modo, i crimini futuri accadranno in un luogo e in un’ora molto prossimi a quelli già accaduti in passato, quindi le aree che vengono considerate a rischio in questo preciso istante, verranno considerate aree a rischio anche in futuro.
Tecnologie anti-crimine, la “multi-vittimizzazione”
La multi-vittimizzazione può avere diverse ragioni. Per esempio una persistente eterogeneità spaziale del rischio, oppure una forte dipendenza degli eventi legate alle azioni criminose. Molto intuitivamente, se si prende in considerazione la categoria di crimine del furto in appartamento, in un contesto urbano molto ampio, è possibile notare come alcuni complessi residenziali siano a più alto rischio di attacco rispetto ad altri. Questo può essere dovuto, da una parte, alla struttura oggettiva dell’abitazione o del complesso di abitazioni (ad esempio, le porte e le finestre possono essere forzate facilmente), dall’altra parte è possibile invece che il comportamento di coloro che abitano le case le rendano meno sicure di altre (ad esempio, assenza da casa per svariate ore del giorno).
In ultima istanza, questo tipo di ragionamento razionale porta il ladro a colpire anche le zone limitrofe. Sulla base di questa assunzione è stato costruito l’algoritmo di “selfexciting” il cui approccio comprende una mappatura della zona dividendola in griglie e una stima del tasso di background (al quale ogni nuovo crimine si presenta nella cella). Quando viene rilevato un nuovo crimine il tasso salirà temporaneamente per poi riscendere nei momenti in cui non si verificano altre azioni criminose, fino a raggiungere nuovamente il tasso di background.
Un’applicazione riuscita dell’algoritmo è stata sperimentata dal dipartimento di polizia di Santa Cruz, California (USA), nel biennio 2010-2011. L’algoritmo è stato sviluppato al fine di predire i crimini contro la proprietà (furti in abitazione o di autoveicoli), ed è stata rilevata una riduzione del 23% dei crimini. Grazie all’uso del modello è stato anche possibile individuare i momenti più comuni degli attacchi (il martedì e il giovedì tra le 17:00 e le 20:00), permettendo agli agenti di allocare le risorse nelle zone calde al fine di prevenire gli attacchi.
Le categorie di modelli illustrate fino a questo punto vengono utilizzate per predire il luogo in cui un’azione criminosa ha più probabilità di essere registrata.
Oltre Minority Report, l’analisi spazio-temporale
Per predire invece il momento in cui si verifica un reato devono essere utilizzati due approcci diversi. Uno di questi è l’analisi spazio temporale che prende in considerazioni diverse variabili: l’ora dell’avvenimento di un crimine; il giorno della settimana; la stagione o le condizioni metereologiche; i fattori ambientali, ad esempio, l’illuminazione stradale e molte altre.
Tutte queste caratteristiche, in combinazione tra loro hanno un valore predittivo nell’individuare i possibili hot spot o le serie criminali: gli esperti hanno individuato nelle loro ricerche come i criminali seriali spesso commettano i reati seguendo schemi prevedibili ad intervalli di tempo prestabiliti. Spesso questi colpiscono sempre in un determinato giorno della settimana, in concomitanza con qualche evento particolare oppure in una data stagione dell’anno.
Il modo più semplice per condurre un’analisi temporale è utilizzando delle heat maps, ovvero delle tabelle che mostrano attraverso l’intensità del colore le frequenze relative dei crimini, riportando la data, l’ora e le condizioni registrate.

La risk terrain analysis, invece utilizza un approccio di classificazione che caratterizza il rischio di reato di una regione in base ai suoi tratti geografici. Il modello è stato sviluppato da Joel Caplan e dai suoi associati presso la Rutgers University, in New Jersey (USA) e valuta i fattori geo spaziali che influiscono sul rischio di criminalità prevedendo in primo luogo una mappatura della zona dividendola in celle.
L’approccio statistico della risk terrain modeling prevede una duplice fase: nella prima, l’algoritmo testa la relazione statistica tra la presenza di determinate caratteristiche geo spaziali in ogni cella del reticolo e la presenza dei crimini di interesse all’interno delle celle. Successivamente vengono prese in considerazione dal modello le caratteristiche di interesse (come ad esempio, luoghi particolarmente a rischio, fermate della metropolitane, stazioni, negozi di alcolici…). Nella seconda fase, l’algoritmo individua le variabili selezionate e presenti in ogni cella, cosicché le celle con il maggior numero di variabili vengono marcate come zone a rischio.
Sebbene entrambe le categorie analitiche servano a prevedere il momento in cui un crimine ha più probabilità di accadere, tramite l’analisi spazio temporale l’analisi è rivolta verso le caratteristiche temporali della location del crimine e attraverso la loro analisi è possibile predire i crimini futuri; mentre tramite la risk terrain analysis il focus è rivolto alle caratteristiche geografiche che definiscono una data regione e contribuiscono ad aumentare le probabilità di rischio di un’azione criminosa futura.
Digitale per la security, il software PredPol
Il PredPol venne sviluppato nel 2013 grazie alla collaborazione tra il dipartimento di polizia di Los Angeles, l’Università di Santa Clara e l’Università della California, in particolare, dal cofondatore Jeffrey Brantigham in collaborazione con la matematica Andrea Louise Bertozzi e George Mohler.
Il software è estremamente efficiente e semplice: funziona tramite un solo algoritmo di machine learning. Il dataset messo a disposizione per la predizione utilizza dati storici (vecchi dai due e i cinque anni) e le variabili tenute in considerazione dal modello sono solamente tre: data, ora e luogo del crimine, tipologia di crimine commesso. Le predizioni vengono proiettate e visualizzate tramite un’interfaccia messa a disposizione da Google Maps che mette in luce gli hot spot, disegnando direttamente sulla mappa quadrati rossi di 150 m2 l’uno.

Il ragionamento matematico che sta alla base della costruzione di PredPol è più complicato. Per il suo sviluppo vennero utilizzati concetti molto simili a quelli che si usano per predire i terremoti e le conseguenti scosse di assestamento. Per individuare gli hot spot vengono utilizzati i modelli ETAS (epidemic-type aftershock sequence); questi modelli si compongono di due caratteristiche principali: la prima componente è costituita dalle condizioni ambientali basate sul modello e sono costanti nel tempo; mentre l’altra è costituita dai cambiamenti dinamici del rischio.
Gli hot spot a lungo termine sono stimati in base agli eventi stessi e non in base alle caratteristiche ambientali fisse di un hot spot (che invece utilizzano come parametri la data e il luogo di attrazione della criminalità). La differenza sostanziale tra le semplici previsione degli hot spot e l’utilizzo dei modelli ETAS consiste nella considerazione degli hot spot di lungo periodo, che non vengono valutati tramite una semplice hot spot analysis.
Grazie alla previsione delle aree calde da parte del modello, ogni 12 ore vengono stilati dei documenti che evidenziano le aree che necessitano di pattugliamento e vengono fornite agli agenti che si muovono di conseguenza. Questo processo permette una migliore allocazione delle risorse di polizia che si dirigono a colpo sicuro verso zone precise della città.
Il modello “made in Italy”: Keycrime
KeyCrime è un software sviluppato a Milano con lo scopo principale di ridurre il numero di rapine nelle farmacie della città metropolitana del Nord Italia. Mario Venturi, un ex-agente di polizia della questura milanese, nel 2007 ha iniziato a lavorare al suo progetto di polizia predittiva collezionando i dati riportati nelle denunce circa i crimini di rapina verso esercizi commerciali. Con l’aiuto di matematici, sociologi, informatici e agenti della polizia più esperti il software ha preso vita ed è attivo ormai da una decina d’anni registrando un calo del 88% circa per i reati di rapine.
L’assunto teorico sul quale si basa la costruzione del modello di previsione è rappresentato dal fatto che i criminali hanno dei comportamenti abituali che rendono le loro azioni future prevedibili. Questa prevedibilità è insita delle peculiarità e nelle attività dei criminali (come ad esempio, le loro abitudini e i luoghi di residenza); le caratteristiche e delle attività delle vittime e l’incrocio tra i tratti distintivi delle vittime e dei criminali.
Gli agenti del dipartimento di polizia milanese svolgono un accurato lavoro di raccoglimento dati contattando le vittime delle rapine poco dopo l’avvenimento del crimine e nei giorni successivi.
Successivamente, il software esamina informazioni sulle rapine (data, ora, luogo, tipo di attività commerciale colpita…), criminali (età stimata, altezza, struttura corporea, colore dei capelli, della pelle, caratteristiche del vestiario…), armi utilizzate durante il colpo (modello, marca, tipo di arma…) e il veicolo utilizzato dal criminale. Questa grandissima quantità di informazioni è necessaria per stabilire dei collegamenti tra le rapine, permettendo di individuare le regolarità potrebbero essere essenziali al fine di predire i nuovi episodi.
Ogni volta che gli agenti inseriscono i dettagli di una rapina all’interno del software, esso è in grado di individuare caratteristiche simili o identiche che delineano una qualche rapina già avvenuta in precedenza; in questo modo il modello collega tra di loro le rapine che con buona probabilità sono state commesse dallo stesso criminale.
Il modello tenta di individuare le cosiddette serie criminali, focalizzandosi sulla possibilità di prevedere non una rapina qualsiasi, bensì la prossima rapina che sarà commessa da quel criminale (o gruppo di criminali) che sono già stati riconosciuti dal modello.
Dall’analisi delle strategie comportamentali dei criminali è stato possibile sviluppare un modello che abbia un approccio di “micro-previsione”, a differenza dei software che usano un approccio di “macro-previsione” e che quindi in seguito alle previsioni degli hot spot stabiliscono le strategie di intervento e di pattugliamento degli agenti, che però non sono mirate verso la tutela di un esercizio commerciale in particolare.
Dall’attenta analisi condotta nei due paragrafi precedenti, i quali illustrano quali sono i punti fondamentali su cui si basano i diversi software, è possibile definire quali sono le differenze tra i due.
Usa e Italia: le differenze tra i due software
In primo luogo è utile sottolineare come l’approccio metodologico tra i due modelli sia completamente differente: il software americano, PredPol, si concentra sull’individuare le zone ad alto rischio di criminalità attraverso una mappatura delle città. Gli hot spot vengono evidenziati dall’algoritmo in particolare sulla base della data e del luogo dei crimini precedenti. KeyCrime, invece non prevede una fase di mappatura della città e una ricerca delle zone ad alto rischio di criminalità, ma si concentra sulla ricerca di tutte quelle informazioni utili a ricostruire le serie criminali.
L’obiettivo specifico di PredPol è quello indirizzare i pattugliamenti verso una zona o più zone specifiche della città al fine di intimidire i criminali a commettere reati o nel caso permette ai poliziotti di intervenire preventivamente in caso di attacco contemporaneo alla loro presenza nella zona. Il software italiano, al contrario, si preoccupa di scoprire, sulla base degli eventi accaduti in precedenza, quale potrebbe essere la prossima mossa di un criminale già individuato e coglierlo in flagrante. Una volta individuata la serie criminale gli agenti iniziano una serie di pattugliamenti direttamente nel luogo dell’esercizio commerciale che ha maggiore probabilità di essere colpito dati gli attacchi precedenti commessi (con buona probabilità dallo stesso individuo o gruppo di individui).
A seguito dell’analisi dei diversi approcci metodologici è possibile delineare alcuni punti che vanno a discapito della funzionalità di entrambi i software e determinare i loro limiti.
Vantaggi e limiti dei due modelli a confronto
Dal momento che PredPol è costruito tramite un algoritmo predittivo di machine learning, una sua cattiva predizione potrebbe rappresentare un grosso limite. Se i dati raccolti tramite le testimonianze delle vittime vengono manipolati o elaborati in modo errato, si presenta il rischio che l’algoritmo fornisca previsioni sbagliate. Allo stesso modo, se vengono inseriti nel dataset i risultati dei crimini precedenti, può succedere che l’algoritmo esegua le stesse previsioni, creando “un loop”. Il problema già esplicato riguarda i pregiudizi razziali, limite concreto nel caso di PredPol dal momento che la previsione potrebbe continuamente offrire come output la segnalazione delle stesse zone calde. In questo modo gli agenti dirigerebbero i propri pattugliamenti sempre verso zone considerate pericolose dal modello creando il pericolo di “ghettizzazione”.
Dall’altra parte, circa l’applicazione del software italiano, un limite riscontrabile è rappresentato dal fattore tempo: gli agenti di polizia impiegano moltissime risorse durante la fase di investigazione e di collezione dei dati. Ad ogni rapina denunciata gli agenti si preoccupano di stilare il verbale direttamente sul luogo del reato e successivamente impiegano molto tempo a ricontattare telefonicamente le vittime (nei giorni successivi, dopo la fase di “post-shock”). Questa fase è necessaria per incoraggiare la parte offesa a ricordare quanti più particolari possibili riguardo le dinamiche e le caratteristiche fisiche e comportamentali del criminale, utili per la ricerca della serie. I dati collezionati vengono poi inseriti nel dataset e analizzati dal modello.
Nonostante le considerazioni tecniche circa i software, l’ambiente in cui essi si sono sviluppati assume una rilevanza assoluta: dallo studio condotto emerge che un’applicazione di KeyCrime in un paese come gli Stati Uniti sarebbe poco proficua. Risulta difficoltoso adottare metodi di investigazione così profondi a causa della dimensione importante delle metropoli statunitensi e costringendo gli agenti ad usare risorse eccessive per la collezione e registrazione dei dati. Una sua applicazione in via sperimentale a livello internazionalepotrebbe però trovare riscontro.
Al fine di comprendere la differenza negli approcci dei due software, è necessaria una riflessione sulla dissomiglianza tra le legislazioni italiana e americana circa, ad esempio, il possesso e l’uso di armi. Il diritto americano prevede la possibilità di detenere armi come strumento di difesa personale e ne è legalizzata la compravendita. La legislazione italiana, invece è una delle più ristrette in Europa e ne prevede il possesso solo tramite una licenza di porto d’armi. Un’interpretazione plausibile sul perché KeyCrime potrebbe funzionare meglio in Italia piuttosto che negli Stati Uniti, si basa sull’assunto che sta alla base della costruzione del modello.
L’ipotesi primaria è che dietro a ogni reato di rapina “ci sia la stessa mano” e identificare la serie criminale risulta efficace per prevenire gli attacchi futuri. Ma nelle città statunitensi è più difficoltoso compiere questo tipo di operazione date le svariate tipologie di armi che possono essere legalmente acquistate dai criminali. Questa libertà rende tutti coloro che possiedono un’arma potenzialmente in grado di compiere un atto criminoso e ciò ostacola l’investigazione e il riconoscimento di un singolo criminale o di una serie.
BIBLIOGRAFIA
Andrew Guthrie Ferguson (2012), Predictive Policing and Reasonable Suspicion.
Di Nicola A, Espa G, Bressan S, Dickson M, Nicolamarino A, (2014) Metodi statistici per la predizione della criminalità. Rassegna della letteratura su predictive policing e moduli di data mining.
G. O. Mohler, M. B. Short, P. J. Brantingham, F. P. Schoenberg, and G.E. Tita, (2011) Self-Exciting Point Process Modeling of Crime, Journal of the American Statistical Association, Vol. 106, No. 493.
G. O. Mohler, M. B. Short, Sean Malinowski, Mark Johnson, G. E. Tita, Andrea L. Bertozzi & P. J. Brantingham (2016), Randomized Controlled Field Trials of Predictive Policing.
Henri Pirkkalainen, Osku Torro (2019) Global Information System Management, Tampere.
Jeffrey A. Rose, Donald C. Lacher (2017) Managing Public Safety Technology. Deploying system in Police, Courts, Corrections, and Fire Organizations, New York.
Johanna M. Leigh, Sarah J. Dunnett, and Lisa M. Jackson, Predictive Policing Using Hotspot Analysis, Hong Kong, 2016
John A. Eterno, Arvind Verma, Eli B. Silverman (2014) Police Manipulations of Crime Reporting: Iniders’ Revelations.
Mastrobuoni G (2014) Crime is Terribly Revealing: Information Technology and Police Productivity.
Lyria Bennet Moses, Janet Chan (2016) Algorithmic prediction in policing: assumptions, evaluation, and accountability.
M. B. Short, M. R. D’Orsogna, P. J. Brantingham, G. E. Tita (2009) Measuring and Modeling Repeat and Near-Repeat Burglary Effects
Muratore M.G. (2011) La misurazione del fenomeno della criminalità attraverso le indagini di vittimizzazione
Walter L. Perry, Brian Mclnnis, Carter C. Price, Susan C. Smith, John S. Hollywood (2013), Predictive Policing. The Role of Crime Forecasting in Law Enforcement Operations.
AI personalizzata per il tuo business: aumenta efficienza e vantaggio competitivo


























