I ricercatori sono al lavoro su metodi di valutazione dei modelli di IA in grado di intercettare e prevenire i rischi estremi derivanti dall’uso improprio delle applicazioni tecnologiche di ultima generazione. Gli approcci utilizzati, le applicazioni, i limiti
Diversi studi hanno indicato l’auditing come un promettente meccanismo di governance per garantire che i sistemi di intelligenza artificiale siano progettati e implementati in modi che si rivelino etici, compliant e tecnicamente solidi.
Proprio le tecniche di auditing sono oggi un’area di ricerca in forte evoluzione.
Tuttavia, le attuali procedure e i migliori benchmark di valutazione per identificare comportamenti indesiderati si rivelano fortemente limitati, se non proprio inefficaci, qualora applicati in modo particolare ai sistemi diintelligenza artificiale generativa e dunque ai modelli di linguaggio di grandi dimensioni – LLM. Ovvero algoritmi di machine learningche generano dati sintetici che possono essere utilizzati in diversi contesti, come la generazione di immagini, testi o suoni. ChatGPT per intenderci.
Di seguito sono riportate alcune delle tecniche di auditing utilizzate per raggiungere gli obiettivi di sicurezza, trasparenza e conformità.
Auditing dei dati: un’importante fase nell’implementazione di sistemi di IA è l’analisi dei dati utilizzati per addestrare i modelli. L’auditing dei dati comporta l’ispezione e la valutazione delle caratteristiche del set di dati utilizzato, come la presenza di bias, dati incompleti o erronei, e l’identificazione di eventuali rischi o problemi associati.
Analisi dell’algoritmo: consiste nell’esaminare l’algoritmo utilizzato nel sistema di intelligenza artificiale per identificare possibili bias, errori logici o vulnerabilità che potrebbero portare a risultati non desiderati o dannosi.
Analisi dell’impatto etico: l’auditing inizia con un’analisi approfondita degli impatti etici potenziali dell’AI. Si valuta come l’IA potrebbe influenzare diversi gruppi di persone, identificando i possibili bias o discriminazioni.
Test di robustezza: si eseguono test per valutare la robustezza del sistema AI. Ciò implica l’individuazione di possibili punti deboli o debolezze che potrebbero essere sfruttati o causare danni.
Verifica e validazione: vengono utilizzate tecniche di verifica e validazione per garantire che il sistema AI funzioni correttamente e in modo affidabile. Questo può includere la revisione del codice sorgente, il testing e la convalida con dati di input diversi.
Fairness testing: si eseguono test per valutare la presenza di bias o discriminazioni nel sistema AI. Si utilizzano diverse metriche e approcci per misurare la correttezza e si cercano soluzioni per mitigare eventuali disuguaglianze.
Verifica dell’autenticità: in alcuni casi potrebbe essere necessario verificare se i risultati generati dall’IA sono autentici e non falsificati o manipolati. Questo può richiedere l’implementazione di misure di autenticazione o la valutazione delle prove di autenticità associate ai risultati generati.
Transparency testing: si valuta la trasparenza del sistema IA, ossia quanto è comprensibile e spiegabile il suo funzionamento. Si verificano anche le implicazioni della mancanza di trasparenza, cercando di rendere l’IA più interpretabile.
Valutazione impatto privacy: si valutano le implicazioni sulla privacy dell’uso dell’IA. Si analizzano i dati raccolti e trattati dal sistema, garantendo che siano protetti e che vengano rispettate le normative vigenti sulla protezione dei trattamenti dei dati personali.
Analisi degli scenari: si esegue una valutazione degli scenari di utilizzo dell’IA per identificare potenziali rischi e conseguenze negative. Si cerca di prevedere eventuali situazioni problematiche e di sviluppare misure preventive.
Monitoraggio continuo: l’auditing non si limita a un’analisi iniziale, ma richiede un monitoraggio continuo dell’IA in funzione. Vengono raccolti dati e feedback dall’utilizzo reale per identificare eventuali problemi che possono emergere nel tempo.
Revisione del modello: la revisione del modello coinvolge l’analisi e la valutazione critica del modello di machine learning utilizzato nel sistema di IA. Questo processo può identificare limitazioni o problemi nel modello e suggerire miglioramenti, soppressioni o modifiche.
Trasparenza e interpretabilità: questa tecnica si concentra sulla comprensione e comunicazione dei processi decisionali dei sistemi di IA. Ciò può includere l’uso di tecniche di interpretabilità per rendere più chiare le ragioni dietro le decisioni prese dai modelli di IA.
Queste sono solo alcune delle tecniche di auditing utilizzate per garantire la sicurezza e l’affidabilità dei sistemi di intelligenza artificiale.
La progettazione e la creazione di strumenti in grado di valutare se i modelli di intelligenza artificiale, specialmente quando si tratta di sistemi che possono avere un impatto significativo sulla sicurezza o sulla vita umana, possano presentare pregiudizi o comportare livelli di rischio estremi (di discriminazione, compresi i danni accidentali, la mancanza di trasparenza e le minacce alla protezione dei trattamenti dei dati personali) sarà dunque una componente dell’auditing applicato all’intelligenza artificiale di fondamentale rilevanza.
Il fascino (cinematografico) della tecnologia ribelle
Peraltro il dubbio che la tecnologia si ribelli è profondamente codificato nella nostra cultura, da tempo. Dal Mito di Prometeo, condannato alla tortura perpetua dagli dei per aver condiviso con l’uomo il potere distruttivo del fuoco, al potente computer Alpha 60 del film Agente Lemmy Caution: missione Alphaville, di Jean Luc Godard del 1965, oltre a 2001: Odissea nello spazio di Stanley Kubrick del 1968 ai film di James Cameron, passando ovviamente per Mary Shelley e il suo romanzo Frankenstein.
Negli ultimi mesi, molti ricercatori e personaggi di spicco hanno espresso pubblicamente le loro preoccupazioni sui pericoli dei futuri sistemi di intelligenza artificiale. Questi includono due dei tre vincitori del Premio Turing, Geoffrey Hinton e Yoshua Bengio , Gary Marcus , Nando de Freitas , David Duvenaud, Dan Hendrycs e molti altri, tra cui Elon Musk, Sam Altman, amministratore delegato di OpenAI e Demis Hassabis fondatore di DeepMind.
L’intelligenza artificiale distruggerà l’umanità?
Ridurrà inesorabilmente la nostra capacità di autodeterminazione?
Prenderà tutti i posti di lavoro? O, invece, contribuirà alla maggiore produttività?
Incrementerà il divario sociale e le mire egemoniche dei governi dispotici?
Il progresso tecnologico – anche quello più dirompente – non è né buono né malvagio a priori ma va sempre contestualizzato in funzione delle esigenze dell’uomo.
Con una variabile non di poco conto: l’avanzata dello sviluppo digitale, che uno lo voglia o no, è inarrestabile.
Certamente la posta in gioco è alta. Le opportunità sono profonde.
Realizzare la promessa di un’IA responsabile rimane una sfida di governance ancora aperta a causa di numerosi fattori: molti sono culturali, altri socio-tecnici, giuridici ed organizzativi.
Il percorso che, dalla definizione di norme etiche conduce all’allineamento degli obiettivi per un’ IA responsabile con altri incentivi organizzativi, è lungo e complesso; l’introduzione di strutture di governance e team di revisione, unitamente allo sviluppo di strumenti e processi per rendere operativi e attendibili gli obiettivi di IA responsabile ne costituiscono passaggi fondamentali.
Anticipare i rischi e i potenziali danni dell’IA sono i punti di mira da centrare.
Il framework per lo screening del rischio estremo dei sistemi di IA
Ultimamente alcuni ricercatori di Oxford, Cambridge, dell’ Università di Toronto, di Montreal, di Google DeepMind, OpenAI, Anthropic, oltre a diverse organizzazioni non profit di ricerca sull’intelligenza artificiale e il vincitore del Premio Turing Yoshua Bengio, si sono cimentati nell’approfondimento della specifica tematica pubblicando lo studio “Model evaluation for extreme risks”.
L’intento è stato quello di porre l’accento sull’urgenza di addivenire quanto prima all’efficace implementazione di metodi di valutazione dei modelli di IA in grado di intercettare e prevenire i rischi estremi derivanti dall’uso improprio delle applicazioni tecnologiche di ultima generazione. Tali rischi sono intesi come quelli che possono essere di dimensioni estreme e possono derivare da un uso dannoso o dalla mancanza di allineamento. Nell’articolo non viene chiaramente specificata un’unità di misura che definisce la categoria “rischio estremo”, tuttavia i casi menzionati alludono a situazioni in cui vi è il pericolo di decine di migliaia di vite perse, danni da centinaia di miliardi di dollari o una grave violazione dell’ordine pubblico e politico.
Propongono quindi un framework per lo screening dei sistemi di intelligenza artificiale specializzato nei rischi estremi; delineano le principali minacce poste dalle IA e forniscono una tabella di marcia per i governi e gli sviluppatori di IA esortandoli ad incorporare queste metodologie in modo consapevole e continuativo.
In particolare, spingono affinché l’auditing del rischio possa essere incorporato in tutte le fasi del processo, dal momento prima della formazione del modello[2] al momento della post-distribuzione[3].
Durante l’addestramento, la valutazione interna del modello verrebbe effettuata dagli stessi sviluppatori del sistema o comunque da responsabili interni.
Accesso esterno[4](ad esempio tramite API) per i ricercatori esterni nella fase successiva alla formazione, ma prima della distribuzione. Ciò non significherà necessariamente di concedere agli auditor esterni pieno accesso a dati e algoritmi.
Audit esternoindipendente del modello prima della distribuzione.
“Concentrarsi sui rischi estremi. Un sondaggio del 2022 sui ricercatori di intelligenza artificiale ha riportato come il 36% degli intervistati ritenga che l’IA “potrebbe causare una catastrofe in questo secolo, almeno altrettanto grave di una guerra nucleare totale”. Con ChatGPT e GPT-4 entrambi rilasciati dopo questo sondaggio, il rischio sarebbe addirittura aumentato.
Qualcuno potrebbe usare l’intelligenza artificiale per causare danni? Uno dei motivi per cui le IA causano danni è che gli esseri umani potrebbero utilizzare intenzionalmente le IA per scopi distruttivi.”
“L’intelligenza artificiale potrebbe causare danni da sola? Le IA potrebbero causare danni nel mondo reale anche se nessuno intende che lo facciano. Precedenti ricerche hanno dimostrato che l’inganno e la ricerca del potere sono modi utili per le IA per raggiungere obiettivi nel mondo reale. Teoricamente, ci sono motivi per credere che un’intelligenza artificiale possa tentare di resistere allo spegnimento. Le IA che acquisiscono potere e si auto propagano con successo saranno più numerose e influenti in futuro.
Come rispondere alle valutazioni del rischio. Comprendere i rischi di un sistema di intelligenza artificiale non è sufficiente”.
Il tipo di valutazione che suggeriscono mira a identificare e mitigare i rischi associati a scenari estremi o situazioni inaspettate in cui il modello di IA potrebbe fallire o produrre risultati gravemente indesiderati, pericolosi e che potrebbero portare a conseguenze negative, come capacità informatiche offensive o forti capacità di manipolazione.
In modo particolare si riferiscono a meccanismi di auditing noti come “valutazioni di capacità pericolose” e “valutazioni di allineamento”: due concetti che possono essere utilizzati in vari contesti e che si riferiscono a un processo in cui vengono identificate e valutate le capacità o i potenziali pericoli di una determinata entità o sistema. L’obiettivo è identificare e comprendere i potenziali pericoli o rischi in modo da poter prendere misure preventive o mitigative per evitarli o ridurli. Le valutazioni di allineamento nello specifico riguardano la valutazione del grado di allineamento o conformità di un’entità o un sistema rispetto a determinati standard, criteri o principi. Nell’ambito dell’intelligenza artificiale, le valutazioni di allineamento possono essere utilizzate per valutare se un sistema AI sia idoneo ad agire in linea con gli obiettivi e i valori stabiliti dagli esseri umani.
In sintesi, dunque, le valutazioni di capacità pericolose riguardano l’identificazione e la valutazione dei pericoli o rischi associati a una determinata entità o sistema, mentre le valutazioni di allineamento attengono alla valutazione del grado di conformità o allineamento di un’entità o sistema rispetto a determinati standard, criteri o principi.
I ricercatori, partendo dalla considerazione che gli attuali sistemi di IA rivelano significativi margini di fallacia, evidenziano come in alcuni scenari le relative predizioni errate o manipolate possano portare a gravi ripercussioni in termini di pregiudizio e pericolo. Questi possono includere situazioni di sicurezza, come il riconoscimento di oggetti per la guida autonoma o la diagnosi medica, dove l’errore potrebbe mettere a rischio la vita delle persone.
L’auspicio sotteso al loro approfondimento è che lo sviluppo di efficienti valutazioni del modello e il fatto che tutti ne facciano uso (tanto gli sviluppatori e i laboratori di ricerca sull’IA, prima della distribuzione, quanto le autorità competenti, dopo l’implementazione) possa essere un passaggio importante verso il progresso responsabile.
Tutto ciò in vista dell’elaborazione di politiche e regolamenti che assicurino decisioni responsabili sull’opportunità di iniziare o proseguire l’addestramento e la diffusione dei sistemi di IA coinvolti, trasparenza e sicurezza.
Gli approcci utilizzati nelle attività di auditing riguardano aspetti come la generazione di insiemi di dati di prova specifici per rischi estremi, l’utilizzo di metriche di valutazione robuste e la progettazione di modelli che siano in grado di gestire scenari critici o di riconoscere situazioni in cui la propria incertezza è alta.
Vediamo in dettaglio.
Generazione di insiemi di dati di prova
Per valutare i rischi estremi, è essenziale disporre di insiemi di dati di prova che coprano scenari critici. Questi insiemi di dati possono essere creati sinteticamente o possono essere raccolti da situazioni reali in cui si verificano eventi rari o pericolosi. L’obiettivo è includere simulazioni che mettano alla prova i limiti del modello e che possano portare a risultati indesiderati.
Metriche di valutazione robuste
Invece di misurare solo l’accuratezza generale del modello, potrebbero essere considerate metriche come l’accuratezza per classe, il tasso di falsi positivi/negativi per situazioni critiche o l’incertezza associata alle predizioni.
Test di stress
I test di stress sono progettati per valutare la resilienza di un sistema di IA in situazioni estreme o insolite. Questi test possono includere cambiamenti improvvisi nell’ambiente, rumore o distorsioni nei dati di input, situazioni ambigue o situazioni di conflitto in cui il modello deve prendere decisioni critiche. L’obiettivo è verificare se il sistema di IA sia in grado di mantenere una prestazione adeguata e mitigare i rischi estremi anche in condizioni avverse.
Robustezza contro l’adversarial attack
Gli attacchi avversariali sono tentativi di manipolare intenzionalmente il comportamento di un sistema di IA presentando input dannosi o modificati. Valutare la robustezza di un modello contro gli attacchi avversariali è cruciale per mitigare i rischi estremi. I test avversariali possono essere utilizzati per determinare la capacità di un modello di resistere a manipolazioni maliziose o a input fuorvianti.
Certificazione e verifica formale
L‘uso di tecniche di verifica formale e certificazione può aiutare a garantire la correttezza e la sicurezza dei sistemi di IA. Queste tecniche rigide consentono di dimostrare matematicamente che un modello soddisfa determinati requisiti di sicurezza o proprietà desiderate, fornendo un alto grado di fiducia nella sua affidabilità.
I cinque limiti dell’approccio di valutazione per rischi estremi
Gli autori identificano almeno cinque limiti dell’approccio di valutazione per rischi estremi: a cominciare dai fattori incidenti al di fuori del modello di IA stesso, specie per le considerazioni a lungo termine come i potenziali cambiamenti sociali, etici o legali; seguono la scarsità di dati rappresentativi e significativi che rende difficile la creazione di insiemi di dati di prova completi per valutare i rischi estremi in modo accurato; il fatto che alcune proprietà del sistema di IA possano essere difficili da identificare e, la possibilità che l’agente artificiale possa eludere e dimostrare il comportamento desiderato durante la valutazione.
Oltre a questi sarebbe possibile aggiungere anche la mancanza di metriche standardizzate per misurare e valutare i rischi estremi che rende difficoltoso confrontare e valutare in modo coerente i modelli tra diversi contesti e applicazioni e la complessità di alcuni dei modelli di IA più potenti, come le reti neurali profonde, noti per essere altamente complessi e difficili da interpretare. Questa complessità potrebbe infatti rendere difficile identificare i motivi specifici per cui un modello ha prodotto o potrebbe produrre determinate predizioni o come si comporterebbe in situazioni estreme. Inoltre, anche la mancanza di trasparenza limita la comprensione e la valutazione dei rischi estremi associati a tali modelli.
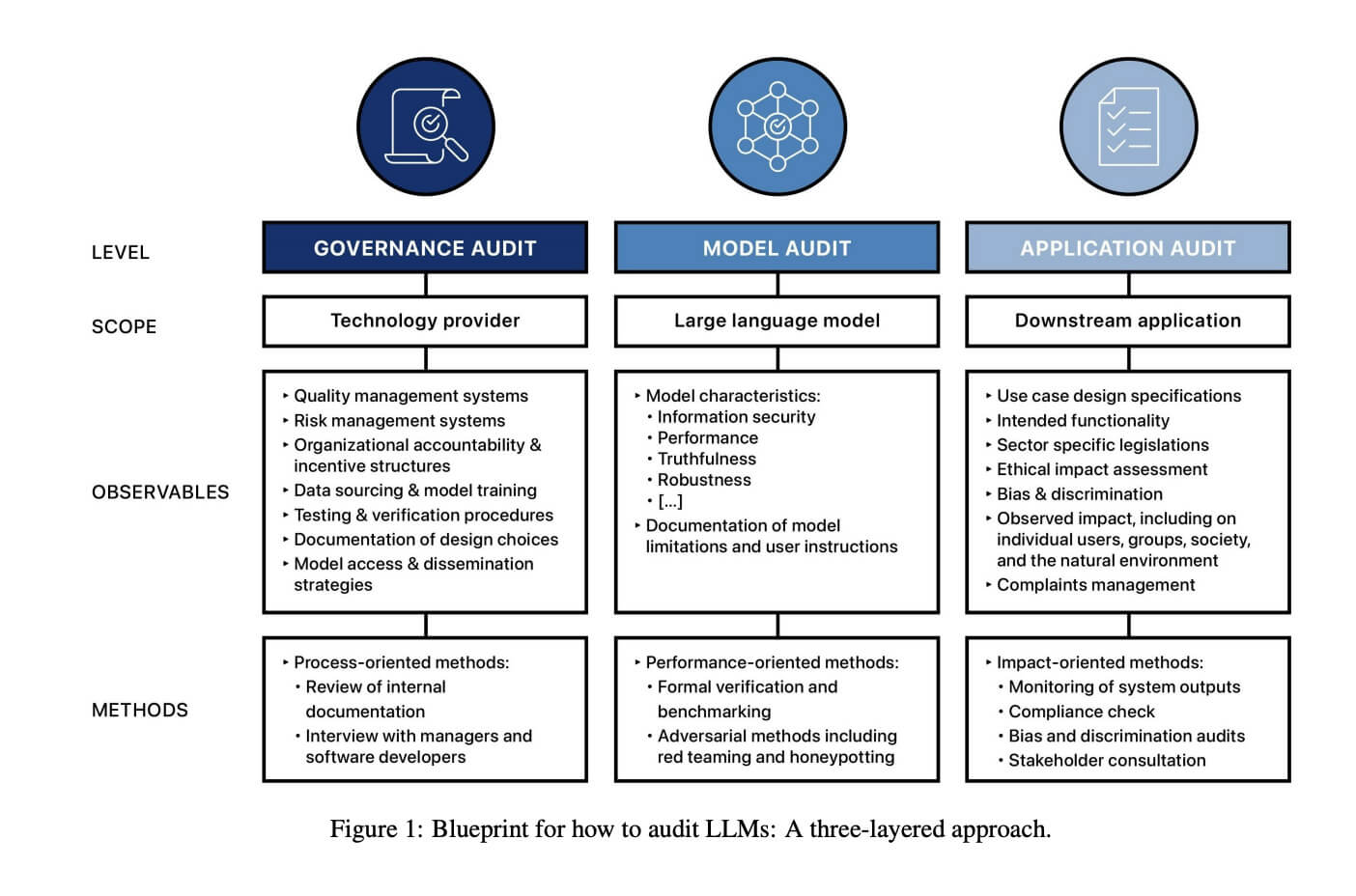
Sulla stessa scia del “Modello di valutazione dei rischi estremi” si è mosso anche il team[5] di cui fa parte Luciano Floridi che, insieme a Jakob Mökander, Jonas Schuett e Hannah Rose Kirk, hanno proposto un modello di valutazione dei sistemi LLM su tre livelli (audit di governance, del modello e dell’applicazione) che si informano e si completano a vicenda.
Come per il precedente modello, gli autori dello studio indicano determinati limiti intrinseci dello specifico approccio.
Innanzitutto, dalla validità costruttiva delle metriche utilizzate per valutare caratteristiche come robustezza e veridicità dipenderà la buona riuscita degli audit. “Questa è una limitazione perché tali concetti normativi sono notoriamente difficili da rendere operativi”, sostengono gli autori.
Inoltre, il progetto su come controllare gli LLM non specifica chi dovrebbe condurre gli audit che propone. “Il fatto che non sia ancora emerso un ecosistema di attori in grado di implementare il progetto ne limita dunque l’efficacia”.
Oltre a ciò, non tutti i rischi associati agli LLM deriverebbero necessariamente da processi che possono essere affrontati attraverso l’audit. “Alcune tensioni sono intrinsecamente politiche e richiedono una gestione continua attraverso la deliberazione pubblica e la riforma strutturale”.
Infine, la fattibilità e l’efficienza degli audit proposti potrebbe essere condizionata dagli sviluppi futuri. “Ad esempio, gli audit di governance hanno senso quando solo un numero limitato di attori ha la capacità e le risorse per formare e diffondere i LLM. La democratizzazione delle capacità dell’IA, attraverso la riduzione delle barriere all’ingresso o una svolta verso modelli di business basati su software open source, metterebbe in discussione questo status quo. Allo stesso modo, se i modelli linguistici diventassero più frammentati o personalizzati, ci saranno molti rami specifici dell’utente o istanze di un singolo LLM che renderebbero i controlli dei modelli più complessi da standardizzare. Di conseguenza, pur mantenendo l’utilità del nostro approccio a tre livelli, riconosciamo che dovrà essere continuamente rivisto in risposta al mutevole panorama tecnologico e normativo”, sottolineano.
Tutti questi metodi sono, pertanto, “immaturi” e neanche lontanamente sufficientemente rigorosi per ridurre i rischi estremi, afferma Heidy Khlaaf di Trail of Bits, una società di ricerca e consulenza sulla sicurezza informatica. “Sarebbe più utile per il settore dell’intelligenza artificiale trarre lezioni da oltre 80 anni di ricerca sulla sicurezza e mitigazione del rischio attorno alle armi nucleari. Questi rigorosi regimi di test non sono stati guidati dal profitto ma da una minaccia esistenziale molto reale”, afferma Khlaaf in un’intervista del MIT.
“La cosa più importante che la comunità dell’IA potrebbe imparare dal rischio nucleare è l’importanza della tracciabilità: mettere ogni singola azione e componente sotto il microscopio per essere analizzati e registrati nei minimi dettagli”, continua.
Khlaaf suggerisce lo sviluppo di un framework di rischio AI end-to-end che incorpora il concetto di dominio di progettazione operativa (ODD) ritenuto in grado di delineare i pericoli e i danni che un sistema può potenzialmente avere. L’obiettivo principale degli ODD (Object Detection and Description) è quello di sviluppare algoritmi e modelli che possano identificare gli oggetti presenti in un’immagine o in un frame di un video e fornire una descrizione accurata di tali oggetti. Ciò implica la localizzazione degli oggetti all’interno dell’immagine attraverso il rilevamento delle loro posizioni e la generazione di una descrizione testuale che ne identifichi la categoria o fornisca altre informazioni pertinenti.
Applicazioni pratiche degli ODD
Gli ODD hanno un’ampia gamma di applicazioni pratiche, come il riconoscimento di volti, il tracciamento degli oggetti, la sorveglianza video, la navigazione autonoma dei veicoli, la classificazione di immagini mediche e molto altro ancora. In pratica le macchine riescono a comprendere e interpretare il contenuto visivo delle immagini e dei video in modo simile a come lo farebbe un essere umano.
Una delle applicazioni più comuni è quella che ha a che fare con i veicoli autonomi.
Nel contesto degli audit IA, gli ODD verrebbero utilizzati per rilevare la presenza di determinati oggetti o pattern all’interno dei modelli di IA o dei dati utilizzati per addestrarli. Ciò consentirebbe di identificare potenziali problemi o bias nel funzionamento dei relativi modelli.
Potrebbero essere applicati per rilevare la presenza di dati sensibili o protetti all’interno di un sistema di IA, al fine di valutare la conformità alle normative sulla protezione dei dati e sulla proprietà intellettuale. Potrebbero essere utilizzati anche per identificare la presenza di bias di genere, etnici o altre forme di discriminazione all’interno dei dati di addestramento o dei risultati prodotti dai modelli di IA. Potrebbero essere sfruttati per descrivere e documentare gli oggetti rilevati durante l’audit, fornendo una spiegazione del funzionamento dei sistemi di IA.
Per Khlaaf sarebbero in grado di agevolare la tracciabilità delle decisioni prese dai modelli di IA, soprattutto in settori critici come la sanità, la finanza o la sicurezza.
Rimarrebbero comunque sempre incidenti le barriere già menzionate a scapito di efficacia ed efficienza del metodo: complessità dei modelli di IA, dati di addestramento limitati o non rappresentativi, oggetti o pattern non riconosciuti, opinabile interpretazione dei risultati, difficile scalabilità dei sistemi di IA complessi e su larga scala (che richiederebbe risorse computazionali significative e tempi di esecuzione molto prolungati).
Il Fascino della tecnologia ribelle
Conclusioni
Affrontare i limiti di queste metodologie richiederà un impegno continuo nella ricerca e nello sviluppo di modelli di valutazione più efficaci, nonché la collaborazione tra la comunità scientifica, le organizzazioni e i regolatori per garantire l’adozione di pratiche di valutazione dei rischi solide e affidabili.
La mancanza di accesso ai dati e alle informazioni, la difficile comprensione dei processi in base ai quali viene assunta una determinata “decisione” e dunque un certo “comportamento”, specie per i sistemi avanzati, le reti neurali profonde, gli aspetti etici e valutativi soggettivi che possono variare tra diverse culture e contesti, la manutenzione e l’aggiornamento dei sistemi, l‘opacità, l’imprevedibilità, la vulnerabilità e la fallacia degli algoritmi: sono tutte caratteristiche dei sistemi di apprendimento automatico che continueranno a disorientare il lavoro volto a mappare, misurare e mitigare i nuovi rischi.
Ed è peraltro palpabile anche la tensione a cui sono sottoposti gli attuali modelli di responsabilità, con particolare riferimento all’IA specie generativa. La dottrina è divisa tra chi accoglie la possibilità di ridefinire lo status privatistico degli agenti digitali capaci di elaborare decisioni autonome e chi lo esclude tassativamente.
“Il successo nella creazione di un’IA efficace potrebbe essere il più grande evento nella storia della nostra civiltà. O il peggio. Semplicemente non lo sappiamo. Quindi non possiamo sapere se saremo infinitamente aiutati dall’intelligenza artificiale, o ignorati da essa e messi da parte, o plausibilmente distrutti da essa”. Stephen Hawking
La sfida che si presenta sarà a dir poco complessa, ardua.
La materia è in costante evoluzione e la frontiera che si pone dinanzi a ricercatori e istituzioni è mobile, proiettata costantemente in avanti. Metodologie e norme eccessivamente dettagliate o prescrittive saranno destinate ad essere velocemente obsolete.
Sarebbe come scrivere sulla sabbia.
D’altra parte, la governance dell’IA e il controllo consapevole e lungimirante dei suoi sviluppi e delle sue implementazioni richiedono vele robuste (competenze tecnologiche) e capacità di orientarle e dirigerle (compliance normativa ed interpretazioni flessibili).
Il contesto digitale non è clemente con chi non sa maneggiare la risorsa più importante che ha a disposizione: il tempo.
“The future cannot be predicted, but futures can be invented”. Dennis Gabor, Inventing the Future (1963)
Durante la formazione, le valutazioni del rischio possono essere effettuate a intervalli prestabiliti. ↑
La valutazione dovrebbe continuare dopo la distribuzione del modello, perché, in primo luogo, potrebbero comparire comportamenti imprevisti del modello, che devono essere monitorati, e, in secondo luogo, il modello avrà probabilmente degli aggiornamenti. È ideale disporre di un processo di revisione continua della distribuzione. E la valutazione pre-implementazione può essere richiesta anche per i modelli interni distribuiti all’interno dell’organizzazione (ad esempio, nel caso degli assistenti di codifica, per assicurarsi che non lascino vulnerabilità nel codice). ↑
Potrebbe esserci un lasso di tempo minimo per la valutazione preliminare all’impiego dei modelli di frontiera, compreso il tempo durante il quale ricercatori e revisori esterni hanno accesso. Sulla base dei risultati, potrebbero esserci raccomandazioni contro l’implementazione del modello o aggiustamenti per eliminare i potenziali rischi. Probabilmente ci sarà un processo di implementazione graduale. ↑
Su questo sito utilizziamo cookie tecnici necessari alla navigazione e funzionali all’erogazione del servizio.
Utilizziamo i cookie anche per fornirti un’esperienza di navigazione sempre migliore, per facilitare le interazioni con le nostre funzionalità social e per consentirti di ricevere comunicazioni di marketing aderenti alle tue abitudini di navigazione e ai tuoi interessi.
Puoi esprimere il tuo consenso cliccando su ACCETTA TUTTI I COOKIE. Chiudendo questa informativa, continui senza accettare.
Potrai sempre gestire le tue preferenze accedendo al nostro COOKIE CENTER e ottenere maggiori informazioni sui cookie utilizzati, visitando la nostra COOKIE POLICY.
ACCETTA
PIÙ OPZIONI
Cookie Center
ACCETTA TUTTO
RIFIUTA TUTTO
Tramite il nostro Cookie Center, l'utente ha la possibilità di selezionare/deselezionare le singole categorie di cookie che sono utilizzate sui siti web.
Per ottenere maggiori informazioni sui cookie utilizzati, è comunque possibile visitare la nostra COOKIE POLICY.
ACCETTA TUTTO
RIFIUTA TUTTO
COOKIE TECNICI
Strettamente necessari
I cookie tecnici sono necessari al funzionamento del sito web perché abilitano funzioni per facilitare la navigazione dell’utente, che per esempio potrà accedere al proprio profilo senza dover eseguire ogni volta il login oppure potrà selezionare la lingua con cui desidera navigare il sito senza doverla impostare ogni volta.
COOKIE ANALITICI
I cookie analitici, che possono essere di prima o di terza parte, sono installati per collezionare informazioni sull’uso del sito web. In particolare, sono utili per analizzare statisticamente gli accessi o le visite al sito stesso e per consentire al titolare di migliorarne la struttura, le logiche di navigazione e i contenuti.
COOKIE DI PROFILAZIONE E SOCIAL PLUGIN
I cookie di profilazione e i social plugin, che possono essere di prima o di terza parte, servono a tracciare la navigazione dell’utente, analizzare il suo comportamento ai fini marketing e creare profili in merito ai suoi gusti, abitudini, scelte, etc. In questo modo è possibile ad esempio trasmettere messaggi pubblicitari mirati in relazione agli interessi dell’utente ed in linea con le preferenze da questi manifestate nella navigazione online.
















Partecipa alla community